
|
|
|
|
|
|
|
One of the major reasons the RIF was redeveloped was because it could no longer be maintained. It developed a critical dependence on a piece of software that could not be substituted and had an impact on the development of the entire code base. One of our major design goals in developing the latest RIF is to make it easier to isolate the scope of dependencies on different technologies so that the code base is robust enough to survive aspects of obsolescence.
Dividing up the code base based on technological dependencies also allows developers skilled in different technologies to work efficiently with one another. For example, the code used to maintain the JavaScript code for client applications is maintained independently of either the Java code used to support the middleware or the PostgreSQL scripts used to set up and configure the RIF database. Isolating code by technology allows the project to leverage the value of different languages and libraries where it will have the most effect.
We must also consider the changing composition of our team and the environment within which we would expect future development to occur. In the past, versions of the RIF were maintained by one or two developers. In the present, multiple developers will work on it in a part time capacity, making contributions that best suit their strengths. In a team of multiple developers, lowering software maintenance costs may mean making it easier to maintain coding that is either divided amongst more developers or consolidated by fewer.
Another consideration for lowering maintenance costs is to lower the skill required by new developers being brought onto the project. Academic projects often have to compete with industry for skilled talent. If the project invests in niche technologies and advanced design features, there is a risk the project will not be able to maintain the code base for the long term because of natural staff turnover. Therefore, it is best wherever possible to make the code base simple enough so that developers with minimal skill can make changes.
Our last major consideration for designing for maintenance is minimising repetitive code. Having fragments of repetitive code in the code base makes the software brittle and more likely to incur errors should a fragment need to change.
This topic is covered in the following sub-sections:
General Design-2 : Organise code using a common three tier architecture that has the following layers: a presentation layer for managing GUI code; a business concept layer for managing the way business concepts are expressed in the system; and a data storage layer for managing the task of reading data from or writing data to the database.
and
General Design-3 : Ensure that the presentation layer only interacts with the data storage layer via the business concept layer. Never let presentation and data storage layer have direct communication with one another.
These two decisions mean that changes made to electronic forms in the presentation layer should not cause changes in the data storage layer. The classes in the business concept layer are designed, wherever possible, to be neutral with respect to how their data are stored or displayed. Therefore, changes in either the presentation layer or the data storage layer should have minimal impact on classes in the business concept layer.
Changes in the business classes will likely cause changes in both the data storage layer and the presentation layer. However, these changes will appear very predictable for developers. For example, if a new field is added to a business class, it will likely cause a new form field to be added in the presentation layer and another field value to set in the data storage layer. A significant number of changes may be needed in the code base, but because most layers will mirror concepts and properties of the business class layer, the changes will likely be predictable.
Maintenance-1 : Leverage the division of responsibilities in the three tiered architecture so that a code change in one layer can have a predictable cascade of changes in other layers.
Where code in one layer cannot be insulated by changes in another, the cascade of changes that are needed should be predictable. The following diagram shows how adding a new field to the Investigation business class could cause changes that ripple throughout the code base.
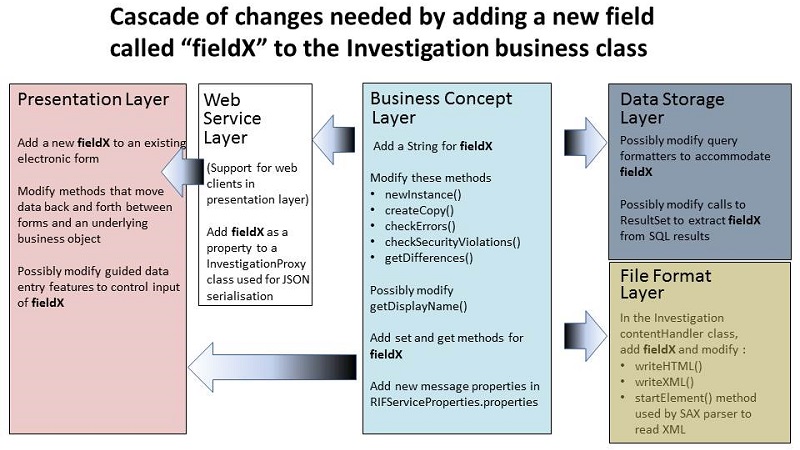 Adding a field to
Adding a field to Investigation would cause changes in
web services that supported browser-based client applications in the presentation layer.
The JavaScript files used to support the browser application would need to be changed
to show the new field values that would be provided by the web services. The original desktop
prototype of the Study Submission Tool does not use web services, so it would respond directly
to changes in the business class layer.
The new field would also cause changes to happen in layers that managed
Investigation data in the database and that serialised the data for file
formats such as HTML and XML.
The powerful influence of changes in the business concept layer on other layers means that new developers will learn the codebase most quickly if they consult the business concept layer first. Once they learn about the business classes and the service APIs, most of other code should appear easier to understand.
Maintenance-2 : Because the business concept layer plays such an important role in the propagation of changes, this is the layer that developers who are new to the code base should learn first.
Next, the code base will be divided up by tool rather than by type of computing concern. The main feature areas of the software are reflected in its four tools, which are listed from most to least development priority:
Although the Study Submission and Study Result Retrieval tools share many features, the rest of the tools do not. Where tools may share an interest in using the same database table fields, they are not likely to interfere with one another. For example, when the Data Loader Tool is loading new data, none of the other tools should be active.
That the tools may use different resources at different times does not mean changes made in one tool will not affect the others. However, they tend to be isolated from one another to help assist a clear division of roles amongst developers.
In our discussion of concurrency, we described one measure where we try to reduce the state of classes used to support service methods:
Concurrency-10 : Where it is possible, favour using method variables over using class variables. Class variables can be accessed by multiple threads, but local variables in methods will be used by only a single calling thread.
Minimising state can help lower maintenance costs as well. If two service methods depend on the same resource, then changes to the way one method uses it may cause concerns about side effects in the other. The less state these methods share with one another, the less the coding of one service method may be influenced by the coding of another.
Although we know that methods do in fact share common resources, the tendency for them to be reasonably independent from one another makes a division of labour by service call reasonable to do. In general, two developers can each be assigned to maintain a specific service method without having too much concern about how their work would effect one another.
The following diagram combines the various strategies we have discussed to divide up the code to divide labours.
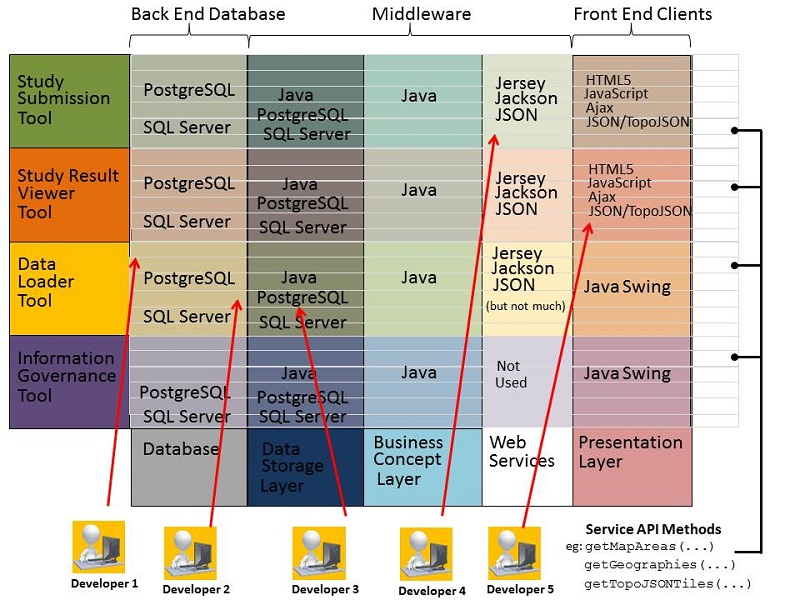
Maintenance-3 : Create a grid showing areas of software maintenance that can be assigned to developers. Create the grid by combining divisions in the code base that are based on:
- computing concern (ie: presentation layer, business concept layer, data storage layer)
- by tool (ie: Study Submission Tool, Study Result Retrieval Tool, Data Loader Tool, Information Governance Tool)
- individual methods of service APIs
Maintenance-4 : Consolidate repetitive code in similar classes using inheritance.
One weakness of developing an inheritance hierarchy of classes is that some subclasses
may not need properties or methods from their superclasses. For example, one of the
basic properties of almost all RIF business classes is an identifier field, which is
meant to hold a primary key that corresponds to a record in the database. For example,
in the class DiseaseMappingStudy the identifier contains a number which
can be linked to an auto-generated primary key in a table describing studies. However,
in the class Geography, identifier is not used at all. This is because
in the database, a geography is identified by its name, which acts as a natural key.
Therefore, an identifier field will likely be used by classes which correspond to auto-generated primary keys, but not those which correspond with natural keys. Despite the awkward fit of the identifier field with some of its subclasses, using inheritance to consolidate repetitive code provides a lot of benefit.
In some parts of the code, we have used inheritance to anticipate future subclasses
that which embody business concepts that are not fully understood. For example, we
currently only support disease mapping studies. However, we will soon be investigating
the properties of risk analysis studies. We have made
rifServices.businessConceptLayer.DiseaseMappingStudy
inherit from rifServices.businessConceptLayer.AbstractStudy because we
anticipate they will share most of the same properties. However, we have developed
the superclass to make it easier for us to move code convergent behaviour into the
AbstractStudy class or divergent behaviour into the DiseaseMappingStudy
and RiskAnalysisStudy classes.
Although inheritance can save work, it can also add unnecessary complexity when the subclass is unlikely to use most of the properties of its superclass. When class B inherits from class A and they have little in common, there can be at least two problems:
Unnecessary inheritance often happens when developers want to subclass Java Swing classes.
Early in development, it was clear that most of the methods in
rifSubmissionTool.desktop.interactive.InvestigationEditorDialog
emphasised application-specific operations rather than some generic UI issue.
Although the InvestigationEditorDialog class was managing UI components,
it had very little in common with a class such as javax.swing.JDialog.
Therefore, we made InvestigationEditorDialog contain an instance of
JDialog. In general it is better to contain rather than inherit from
Swing classes.
Maintenance-5 : Avoid unnecessary inheritance when the super class and sub class would have little to do with one another. For example, in many cases, a class should contain rather inherit from a Java Swing class.
Inheritance works best if class A is a kind of class B. However, in other scenarios, the classes may not be similar enough for a superclass-subclass relationship to support sharing code. For example, many classes may want to use a logging class to audit actions, even though the logger class may have nothing in common with them.
In this case, we consolidate repetitive code into utility classes that can be used in multiple parts of the code base. Now that we have identified patterns that would support sharing code through inheritance, we're now interested in sharing code through aggregation. Specifically, we are looking for patterns that would lead us to say:
The following table shows examples of where we found repetitive code being used by dissimilar classes. In each case, we consolidated repetitive code through the creation of new classes.
| Common need shared by dissimilar classes | Class |
| auditing actions using a log |
rifServices.util.RIFLogger
|
| checking for malicious String values auditing actions using a log |
rifServices.util.FieldValidationUtility
|
| constructing an SQL SELECT statement |
rifGenericLibrary.dataStorageLayer.SQLSelectQueryFormatter
|
| creating and initialising Java Swing components |
rifGenericLibrary.presentationLayer.RIFUserInterfaceFactory
|
| generating fragments of HTML |
rifGenericLibrary.presentationLayer.HTMLUtility
|
| rendering a list containing alphabetically sorted list items |
rifGenericLibrary.presentationLayer.OrderedListPanel
|
Maintenance-6 : Consolidate repetitive code in similar classes using inheritance.
Now that we have minimised repetitive code and organised it so that it can be maintained by multiple developers, we need to minimise the skill needed to maintain the code base.
Relying on just a code base to guide future developers is problematic because it represents the outcome of design rather than the process of decision making which led to it. Lowering maintenance costs involves encouraging future developers to reuse existing code as much as possible.
A well described design can help developers decide whether they should retain, alter or retire code structures that would otherwise just carry legacy maintenance costs. Without sufficient information about a code base's design, developers tend to adopt a policy of avoidance in changing existing code. Instead, they invest in creating new code structures that will make sense in the context of their current coding activities.
An architecture can provide scaffolding with which other developers can add enhancements. It can tend to non-functional software concerns such as testability, security and concurrency, which can require a high level of skill. It can also isolate areas of the code base, either to identify areas that require specialist knowledge, or plugin areas that could be coded with more generalist knowledge. But all of these features only have value if they are explained somehow.
In many projects, knowledge about the design will be conveyed orally as one developer passes along their knowledge to the next. However, if we assume a future development environment of scarce resources, it makes sense to invest effort in conveying this knowledge through formal documentation.
Maintenance-7 : Invest in making this design manual. It can help future developers determine which code structures should be adapted, left alone or discarded. If they can reuse existing infrastructure, it means that the task of writing new code can remain an option rather than a requirement.
Our coding philosophy describes the importance of coding to convention over coding to circumstance. Adopting best practices allows developers with little experience to modify or create high quality code without their knowing how their actions achieve this.
Adapting coding conventions allows them to know where they should make changes in the code base. When code bases become large, they can be intimidating for novice developers who may not know how to modify it. However, if packages, classes, methods and variables follow conventions, it becomes easier for them to navigate through thousands of lines of code.
Through our use of open source technologies to code the RIF, we will lower the monetary cost for projects to use it. However, by using technologies that may be horizontally integrated through common standards rather than being vertically integrated within tools by the same vendor, we can make the code base brittle. If one of the open source technologies we use becomes obsolete, we need a way to substitute it for another technology.
Isolating code that relies on different technologies makes it easier to match skilled developers with development tasks that require niche knowledge. It also helps maximise the amount of code that developers with less skill can maintain.
We have used different techniques to isolate the following parts of the code base that reference various technologies:
PostgreSQL
and SQL Server work.
Node.js
R to apply Bayesian smoothing statistics methods to
study results.
Our use of the three-tier architecture allows us to insulate the presentation layer
and the business concept layer from the way SQL queries are executed with PostgreSQL
or SQL Server databases. In the past we have tried to hide as much
vendor-specific database code in stored database procedures. However, we now expect
that the middleware may have to construct vendor-specific database code. When this happens,
the impact of changes should not affect code in the other two main layers of the architecture.
In some cases, we have used inheritance to help hide a technology from its
sub classes. For example, the only references to the Jackson project are within
protected methods that begin with "serialise".
In other cases, we've relied on aggregation to hide references to other technologies.
We have experienced problems incorporating the Log4J logging framework into the
software. We eventually disabled it until we have time to address the problem. However,
we minimised the impact of the problem by hiding its use within the class
rifServices.util.RIFLogger.
Sometimes we have managed to reduce the impact of a technology on the code base by creating more code instead of less code. Jackson makes use of Java XML bind annotations in a class so that it can determine how to serialise the fields as a JSON String.
We could have marked up the classes in the business concept layer using these annotations.
However, we realised that sometimes JSON could be displayed more efficiently if the annotations
were use in one way instead of another. For consider a web service returning a collection
of rifServices.businessConceptLayer.MapArea objects.
The service could return an array of individual objects such as:
[{"gid":1,"id":"manc-1","label":"Manchester"},
{"gid":2,"id":"camb-glouc","label":"Cambridge, Gloucestershire"},
{"gid":3,"id":"camb-cam","label":"Cambridge, Cambridgeshire"}]
Alternatively, it could return a collection of parallel arrays, which may be
more amenable to being rendered in a table than the format above.
[{"gid":['1', '2', '3']},
{"id":[ "manc-1", "camb-glouc", "camb-cam"]},
{"label":["Manchester", "Cambridge, Gloucestershire",
"Cambridge, Cambridgeshire"]}]
If we are trying to rely on Jackson to render JSON, then the way we make annotations
can affect the way it would attempt to render one of these two formats. Rather than
trying to adapt the business classes, we decided instead to develop corresponding
proxy classes whose sole purpose was to support JSON serialisation for the web
pplications.
All the code which relies on Jackson or Jersey has been isolated in the package
rifServices.restfulWebServices, which could help insulate the rest
of the code base when these two projects are modified or subsituted with other
software solutions.
Maintenance-7 : Use techniques involving inheritance, aggregation or the creation of parallel classes to help insulate parts of the code base from references to other technologies.
Maintenance-8 : In order to hide the use of technologies which are not based on Java or have a complicated tool chain, wrap them using a web service.